
如果你是存储采购、芯片从业者或硬科技创业者,欢迎关注本号,一起追踪这个行业的底层变化。
2026年7月2日,全球存储芯片板块经历了一场罕见的同步暴跌。A股存储芯片指数单日收跌5.67%,兆易创新跌停;隔夜美光科技跌逾10%,韩国三星和SK海力士均跌超9%,KOSPI指数暴跌7.89%触发熔断。
但如果只看这些数字,你会错过这场暴跌里最值得追问的问题:同样是AI芯片,为什么美光能跌10.57%,以英伟达为龙头的费城半导体指数"只"跌了6.27%——存储的跌幅整体比GPU整整多出一倍?同样是芯片公司,暴跌之后各自的处境为什么天差地别?
这篇文章要做的不是复盘"谁跌了多少",而是帮你搭建一个框架——从产业链位置、商业模式和成本结构三个维度,重新理解这轮AI硬件大分化。读完你会发现,7月2日不是故事的终点,而是一面镜子。
一、黑色交易日:三件事撞在了一起
7月2日的暴跌不是某一个利空砸出来的,而是三个变量在同一个时间窗口集中释放。
第一记重锤来自Meta。
7月1日,外媒报道Meta正制定云基础设施业务计划,拟向外部客户出租AI算力和模型使用权。这是ChatGPT时代以来,第一次有头部云厂商主动"卖算力"。
市场解读迅速极化。看多的一方认为,Meta终于找到了让巨额资本开支产生直接回报的路径,这也是为什么Meta当日逆势大涨8.8%。看空的一方关注的是另一层含义:Meta为什么有多余算力可卖?如果连Meta的GPU集群都存在闲置,整个AI基建的投资回报率是否需要重新定价?
对存储而言,这层焦虑的杀伤力尤其直接——如果GPU过剩,HBM和服务器DRAM的需求预期就得一起下修。
第二记重锤来自法院。
6月25日,美国加州北区联邦法院正式受理了一桩针对三星、SK海力士和美光的反垄断集体诉讼。原告指控三大巨头自2022年起协同减产、操纵DRAM价格,四年累计涨幅约700%。
这桩诉讼的威胁不仅是罚款——2002至2005年那轮DRAM价格操纵案曾导致三星、海力士合计被罚超7.3亿美元。更关键的是,如果垄断指控坐实,监管机构可能要求结构性拆分或强制降价。对于一家存储厂的估值来说,这不是"罚多少钱"的问题,而是商业模式的根本性风险。
第三记重锤来自筹码结构。
兆易创新在7月2日之前年涨幅接近300%,股价从年初不到200元一路攀升至694.81元后放量跌停,单日成交额突破304亿元,居A股全市场第一。这不是普通的回调——放天量的跌停,是典型的机构集中出货信号。澜起科技同日下跌14.80%,香农芯创从52周最低32.70元一路涨至306.25元后,获利盘同样极其集中。
三个因素叠加在一起,传递了一个清晰的信号:这一次不是基本面坏了,是估值和筹码先撑不住了。
但最有意思的反差出现在另一边。就在暴跌前一天,全球近20家模拟及功率芯片企业——德州仪器、英飞凌、意法半导体等——集体启动了2026年的第二轮涨价,AI数据中心用的电源管理芯片涨幅达15%至25%。WSTS在春季预测中,将2026年全球半导体市场规模上调至1.51万亿美元,其中存储芯片预计同比增长250%。DRAM和NAND库存仅2至4周,远低于8至12周的安全线。英伟达CEO黄仁勋在暴跌前一周的股东大会上刚刚说过一句话:这轮AI基础设施建设"将以数十年为尺度来衡量"。
基本面没坏,股价却崩了。要理解这一天,不能只看消息面。
二、存储与GPU的核心差别:产业链位置、商业模式与成本结构
同一个AI浪潮里,为什么存储的跌法和GPU截然不同?先看一组对比:7月2日,美光跌了10.57%,A股存储芯片指数跌了5.67%,兆易创新跌停,澜起科技跌了14.80%,韩国三星和SK海力士均跌超9%。而代表GPU和逻辑芯片的费城半导体指数当天跌了6.27%——英伟达作为指数最大权重,跌幅与指数相当。同样是"AI芯片",存储的跌幅整体比GPU多出一倍。而且这不是第一次——回溯过去两年,存储和GPU的节奏本就不同步:2023年,大模型爆发让英伟达股价率先起飞,而三星、美光还在周期底部巨亏;2024至2025年,GPU涨完第一波后,HBM缺货才把存储从底部拉起来,形成一轮"补涨";到2025年底GPU涨幅开始趋缓时,存储反而因为涨价弹性后来居上——闪迪2026年上半年以858%的涨幅登顶标普500。两个板块始终在交替领跑,从未完全同步,7月2日的暴跌不过是把这种结构性差异推到了极致。
这不是偶然的"谁被错杀"的问题,而是这两类芯片在产业链中的位置、商业模式和成本结构,从根上就决定了它们对波动的敏感度完全不同。
2.1 产业链位置:伴生位 vs 卡位
在一台AI服务器中,GPU是"大脑",HBM和DRAM是"短期记忆",NAND和SSD是"长期记忆"。"记忆"的规模完全取决于"大脑"的规模——你装多少GPU,就得配多少内存。
这意味着存储处于AI算力产业链的"伴生位":需求不是独立产生的,而是由GPU出货量衍生出来的。当GPU出现需求疑虑——比如SemiAnalysis在6月30日曝出英伟达在GTC 2026上发布的四芯片Rubin Ultra在三个月后即被取消、回退至双芯片设计——存储的衍生需求逻辑第一个动摇。
GPU则完全不同。AI模型必须跑在GPU上,这是计算入口,不是配套。需求来自模型训练和推理的刚性增长,不会因为"某个云厂商多买了几千张卡"就被怀疑。
一个量化对比可以帮你直观感受这种差异。单台NVL72服务器中,GPU的货值约240万美元,配套HBM约36万美元。存储是GPU的"影子产业",一台机器少配两张卡对GPU厂商是少卖两张卡,对存储厂商是少卖两份内存——而且市场会把这份"少了"的情感加倍投射到股价上。
产业链控制力也完全不在一个量级。HBM4的规格由英伟达主导提出,存储厂的角色是"配合实现"而非"定义规则"。甚至连算法层面的变化——像谷歌在ICLR 2026上发表的TurboQuant,通过压缩KV Cache将推理阶段的内存需求压缩至原来的六分之一——都可以直接动摇市场对存储长期增长的叙事。GPU的叙事则更难被单篇论文击穿:即使算法效率提升,整体算力总需求仍被更大模型和智能体应用推高,这就是经典的杰文斯悖论。
此外,NVIDIA Rubin Ultra的"三个月取消"事件也深刻揭示了GPU自身的风险并非不存在。原方案的四芯片设计要用到超大尺寸的CoWoS封装基板,这种基板在制造时翘曲严重、良率爬不过去,最终只能回退双芯片。这意味着,即使是GPU龙头也会在工艺边界上踩坑。但对存储来说,GPU踩坑的代价不是"英伟达少赚",而是"整条存储链的需求跟着缩水"——因为HBM和先进封装的产能都是锚定特定GPU型号提前规划的,GPU改方案,存储就得重算需求。
2.2 商业模式:标准化大宗品 vs 生态化差异品
理解了产业链位置,再看商业模式,存储和GPU的分化就更清楚了。
传统DRAM和NAND是高度标准化的产品。DDR5就是DDR5,三星造的、SK海力士造的和美光造的,在功能上可以互换。标准化意味着三件事:定价权在买方、切换供应商成本几乎为零、价格纯粹由供需缺口决定。2023年的存储寒冬就是经典案例——需求一收缩,价格雪崩,头部厂商单季巨亏数十亿美元。
GPU则是另一套逻辑。英伟达卖的不仅是芯片,而是CUDA软件生态。一个AI公司要从英伟达切换到AMD,不仅需要重新采购硬件,还得重写数以万计的CUDA代码、重新优化模型、重新训练——这个转移成本高到大多数公司根本不会考虑。转移成本越高,定价权越强。这也是为什么英伟达毛利率稳定在70%以上,而传统存储在周期底部毛利率可能跌破20%。
但HBM正在改变存储的定价逻辑。HBM需要和GPU联合设计、联合验证,从流片到认证通过通常需要12至18个月。一旦通过认证,GPU厂商不会轻易切换供应商——因为这相当于换一块"大脑的瞬时记忆区",风险收益完全不成比例。三星、SK海力士和美光已经和微软、谷歌等云厂商签订了覆盖到2027年的长期锁价协议。HBM的收入正在从"现货定价"转向"合约定价",商业模式越来越像台积电的代工——客户提前预订产能、锁定价格、共同承担良率爬坡的风险。这正是美光在最新财季交出84.9%毛利率的底层密码。
但要注意一个关键事实:2026年HBM在全球DRAM市场中的占比估计仍在20%至30%之间,绝大部分存储收入仍然来自标准化的传统DRAM和NAND。存储行业的商业模式正在"半转型"——一部分收入有了合约的稳定性,另一部分仍然是纯周期定价。市场前期的定价给了"全面转型"的估值,一旦增量叙事出现裂痕、叠加韩国800万亿韩元的五年扩产计划(DRAM产能翻倍)的远期供给预期,估值回调就不奇怪了。
2.3 成本结构:重资产的宿命 vs 轻资产的弹性
第三个维度经常被忽略,但它可能是最根本的——两家公司在需求下行时的"退出成本"完全不同。
存储芯片厂是典型的IDM模式,从设计到晶圆制造到封装测试全部自己做。一座先进DRAM厂的CAPEX在150亿至200亿美元之间,固定资产折旧和产线维护是每天都要烧的固定成本。所以存储厂"停不起"——需求下行时,停产意味着巨额亏损,降价卖至少还能收回一部分现金。这就是为什么存储行业的周期底部总是"血流成河":工厂不能停、库存一直在累积、价格螺旋下降。2023年的周期底部,美光单季亏损超过20亿美元。
GPU厂商是Fabless模式,制造外包给台积电。R&D和软件是核心成本,没有工厂空转的压力。需求下行时,减少下单即可,收入虽然下滑但毛利率不会崩盘,更不会巨亏。2023年存储水深火热的时候,英伟达同期仍然保持盈利。
这个差异的启示很直接:同样的行业逆风,存储厂是被动承受者,GPU厂是主动调整者。两者的股价波动幅度天然就不在一个量级上。
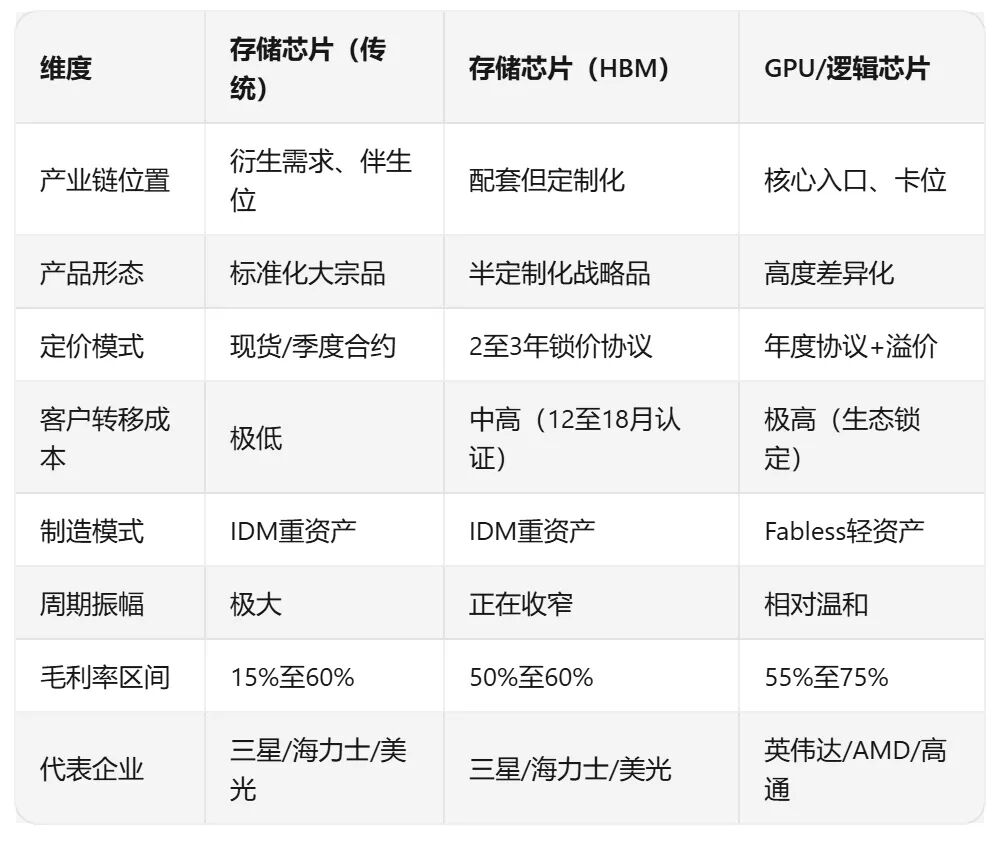
一张表帮你记住这三个维度的差异:
三、中国企业的危与机
前面的框架说明了一个道理:同一场暴跌中,产业链上不同位置的企业,所承受的冲击和所拥有的选择截然不同。这个道理对中国企业同样适用。
3.1 标准存储颗粒企业
以兆易创新为代表,NOR Flash和利基型DRAM处于存储产业链最商品化的环节。
面临的挑战很现实。年涨近300%之后的跌停释放了一个明确的信号:市场在给"AI概念溢价"时,需要区分"真AI存储"(HBM、服务器DDR5)和"传统存储"(消费级NOR、利基DRAM)的估值逻辑——前者有合约定价和定制化壁垒,后者仍然是纯周期。韩国800万亿韩元的扩产计划更指向远期供给压力:五年后DRAM产能翻倍,即便届时AI驱动的需求总量翻数倍,传统消费级DRAM的定价权是否还能维持在目前的高位,存在很大不确定性。
但机会同样存在。利基型存储——比如车规级NOR Flash、IoT设备用DRAM——和AI数据中心的存储是两个相对独立的市场。三大巨头将先进产能全力转向HBM,反而压缩了传统消费级DRAM和利基型存储的供给。这种"产能被高端产品挤占"的效应,对中低端存储的价格反而是支撑。长鑫存储和长江存储在国产替代逻辑下,如果登陆资本市场,它们面向的国内数据中心和消费电子市场将获得独立于全球周期的估值体系。
3.2 存储接口芯片企业
以澜起科技为代表的内存接口芯片企业,商业模式更接近"逻辑芯片"。
短期来看,同样无法独善其身——7月2日澜起科技下跌14.80%。DDR5的渗透率已过半,下一阶段的增长引擎MRDIMM和CXL的放量节奏取决于服务器平台的换代速度,存在时间窗口风险。
但从商业模式来看,澜起和兆易创新的"跌法"逻辑完全不同。DDR5 RCD芯片已经做到9200MT/s,每一代内存标准的接口芯片都需要重新设计、重新认证,全球只有两到三家供应商。这种"跟着标准迭代走、不需要看存储价格脸色"的商业模式,天然比标准颗粒的周期振幅小得多。随着AI推理时代对内存带宽的持续渴求,MRDIMM和CXL是结构性升级的大方向,而非短期景气度波动。
3.3 存储分销与模组企业
以香农芯创、江波龙、佰维存储为代表的分销和模组企业,是产业链中对价格最敏感的环节。
香农芯创2026年一季度净利润同比暴增7835%,单季利润超过2025年全年2.43倍,股价从52周最低32.70元涨至306.25元。这个数字的背后是典型的"周期放大器"效应:分销商在涨价周期中,低价库存持续升值,利润弹性远超上游制造端。但这条弹性曲线的对称面是:跌价周期中,存货减值损失同样剧烈且来得极快。业内目前2至4周的极低库存水位,意味着本轮补库行情可能已接近尾声。
江波龙和佰维存储的模组业务,在涨价周期中买颗粒、卖模组,库存增值效应几乎是立竿见影的。但这份弹性需要付出另一种代价——没有自己造颗粒的能力,意味着没有定价权。转向企业级SSD和服务器内存模组,是从"赚差价"的模式转向"赚附加值"的模式。香农芯创作为SK海力士的核心代理商,在HBM供不应求的背景下,代理权的稀缺性本身是一份资产。
3.4 下游AI与硬件公司
对于使用存储的下游企业,这次暴跌提供了一个重新审视成本结构的契机。
HBM、DRAM和SSD在一台AI服务器中的硬件成本合计占比可达15%至25%。存储价格的持续上涨对AI算力供应商和硬件公司是不小的利润挤压。如果AI商业化进展不及硬件投入增速,这层压力会愈发突出。
但硬币的另一面更为长期。谷歌的TurboQuant证明KV Cache可以在零精度损失的前提下压缩到原来的六分之一,等效于内存需求降低——算法效率提升可以从根本上对冲硬件成本。中国公司在这条路上的探索更早。DeepSeek等模型已经向行业展示了"算法创新绕开硬件瓶颈"不只是一句口号。
对AI应用层公司而言,硬件成本下降——无论是通过降价还是通过效率提升——是结构性的长期利好。更深一层,存储价格上涨倒逼算法效率提升,效率提升反过来降低AI部署的门槛、加速商业化落地,这正是技术史上反复出现的杰文斯悖论。
结语
7月2日的暴跌不是AI存储故事的终点,而是一面镜子。
同一面镜子里,站在产业链不同位置的企业,反射出截然不同的影像。存储行业正站在一个十字路口:一半收入仍在传统周期中沉浮,另一半正通过HBM的定制化走向更稳定的商业模式。中国企业要做的,不是争论"该不该买存储股",而是先看清自己在产业链的哪个位置——在伴生位还是卡位、在标准品还是定制品、在重资产还是轻资产——然后才知道,一次暴跌对自己意味着什么。
周期不会消失。但理解周期的人,可以不那么被动地活在它里面。
引用来源
文中股价行情数据综合自上海证券报、21世纪经济报道及各交易所;Meta出售算力、反垄断集体诉讼、Rubin Ultra取消、韩国扩产计划、芯片厂涨价等信息来自相关公司公告、法院文件及媒体报道;行业预测数据引自WSTS、各公司财报及SemiAnalysis。
本文有AI辅助。文章内容仅代表产业分析视角,不构成任何投资建议。
资讯来源:微信公众号






